Im ersten Teil zu Python: Datenanalyse mit Pandas und Co habe ich Euch gezeigt, wie Daten aus Excel-Dateien in Pandas eingelesen und verarbeitet werden können.
Anhand der verwendeten Beispieldaten haben wir Kennzahlen aus der agilen Softwareentwicklung berechnet. Die Beispieldaten und der Quellcode dazu befinden sich in einem Repository auf Github (siehe Quellenverzeichnis).
In diesem zweiten Teil werden wir die ursprünglichen Daten nun grafisch aufbereiten. Dazu verwende ich Altair. Diese Python-Bibliothek dient zur deklarativen Visualisierung für Python und harmoniert perfekt mit Pandas Datenstrukturen.
Encoding: Altair Grundlagen
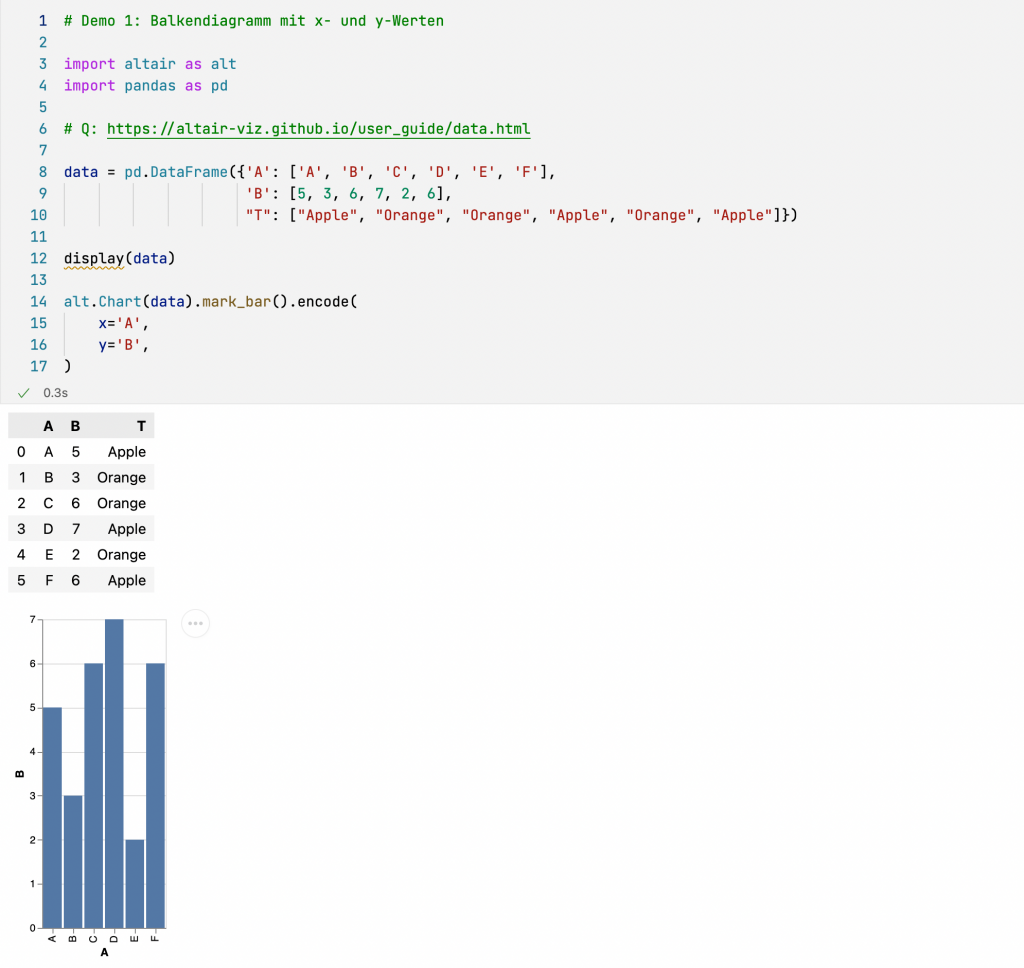
Zum Eingewöhnen zeige ich Euch zwei einfache Beispiele aus der Doku von Altair, um dabei die grundlegenden Konzepte zu erläutern. Der Schlüssel zur sinnvollen Aufbereitung von Daten ist die Abbildung von Eigenschaften der Daten auf grafische Elemente. Altair nennt diese Abbildung von grafischen Eigenschaften auf Datenstrukturen (typisch: Spalten von DataFrames) encoding. Diese erfolgt meistens durch die Methode Chart.encode().
Die einfachste Form ist, Daten auf eine x- und eine y-Achse zu verteilen. Die Methode mark_bar() erzeugt ein Balkendiagramm. Die Abbildung auf die x- und y-Achse des Diagramms erfolgt durch die entsprechende Zuweisung im Encoding. Datentypen ermittelt Altair aus den Metadaten des DataFrames korrekt.
Im zweiten Beispiel nehme ich die Daten aus der dritten Spalte des DataFrames hinzu. Die Spalte ‘T’ bilde ich auf die Verwendung von Farben ab. Nur um hier auch einen anderen Diagrammtyp zu zeigen, habe ich als Diagrammtyp ein Liniendiagramm (mark_line()) verwendet. Eine mögliche Variante, die Farbgestaltung zu beeinflussen, ist die Verwendung eines vordefinierten Farbschemas (alt.Scale(scheme="schema name"), siehe Quellenverzeichnis).

Agile Metriken: Lead Time
Boxplot-Diagramm
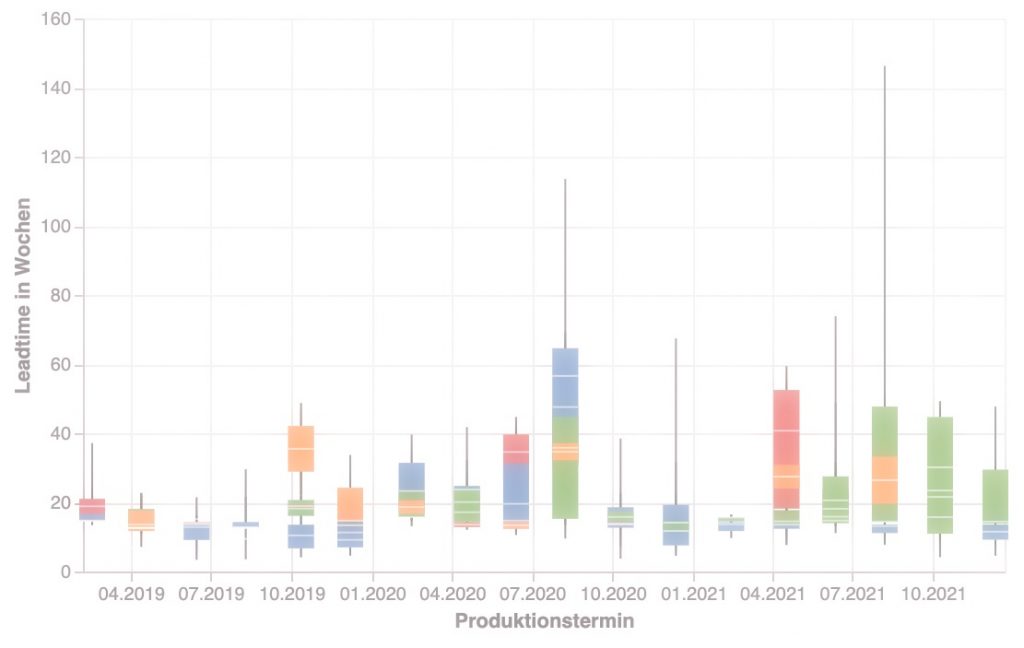
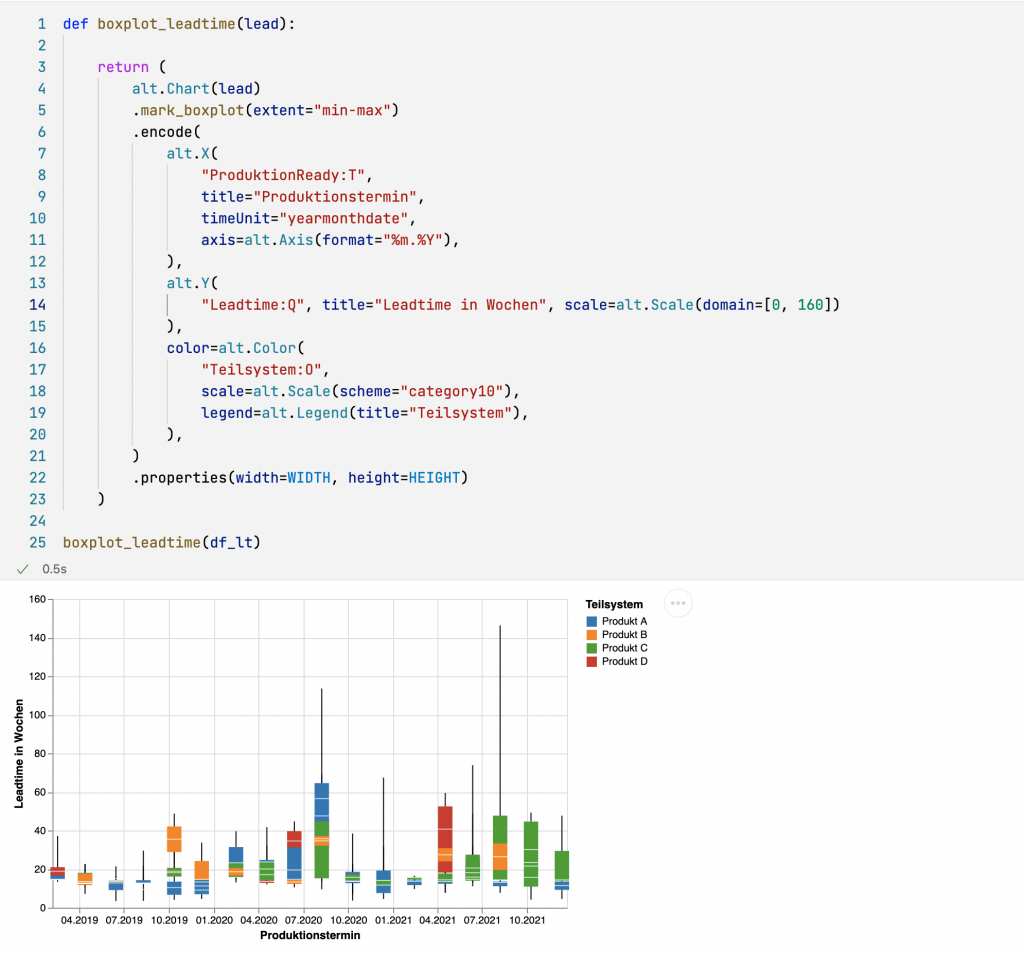
Nach diesem kleinen Aufwärmen schauen wir uns nun die Lead Time etwas genauer an. Im ersten Teil haben wir diese berechnet und das Ergebnis in einem DataFrame df_lt abgelegt. Unser DataFrame enthält zu jedem Arbeitspaket die Information, zu welchem Teilsystem es gehört, wann es in Produktion gegangen ist (‘ProduktionReady’) und wie lange die Entwicklung gedauert hat (‘Leadtime’). Diese Informationen möchte ich nun auf der Zeitachse abbilden.
Das Boxplot-Diagramm ermöglicht die Visualisierung einfacher statistischer Größen wie Median, unteres und oberes Quartil sowie Min- und Max-Werte.
In Zeile (8) weise ich die Spalte ‘ProduktionReady’ der X-Achse zu. Dabei lege ich fest, diese Spalte als Datumswert zu betrachten (‘:T’: Temporal Datentyp). Die Zuweisungen zu timeUnit in Zeile (10) und axis in Zeile (11) dienen der Gestaltung der Achsenbeschriftung.
In Zeile (14) lege ich für die Y-Achse die Skala unabhängig von den im Datensatz enthaltenen Werten fest. Dies wird erst im nächsten Beispiel relevant.
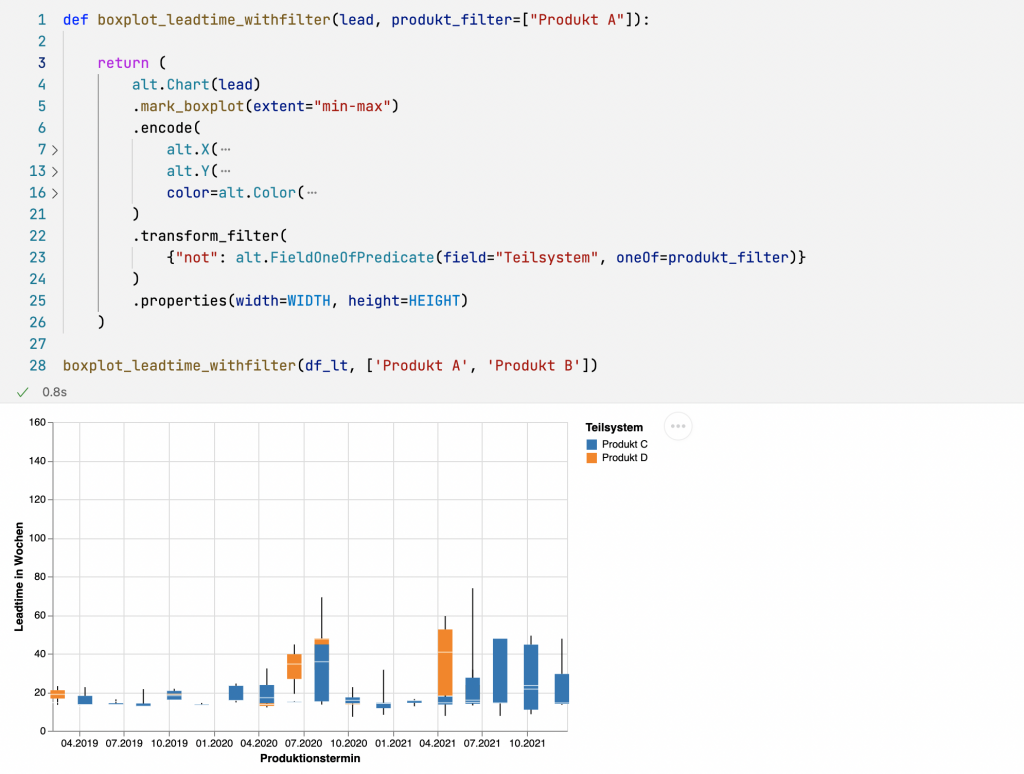
Die Daten sind für die einzelnen Produkte recht unterschiedlich, was das Diagramm auch etwas unübersichtlich macht. Daher füge ich im nächsten Schritt einen Filter auf die Spalte Teilsystem hinzu (Zeile 22–24). Damit kann ich auf einfache Weise von außen beim Aufruf der plot-Funktion steuern (Zeile 28), welche Produkte im Diagramm nicht gezeigt werden sollen. Im folgenden Beispiel zeigt sich auch die Auswirkung der von mir fest vorgegebenen Skala für die y-Achse (0…160).
Histogramm
Ein Maß für die Prozessgüte ist die Streubreite der Lead Time. Dies kann mit einer Häufigkeitsverteilung der Werte für die Lead Time gut visualisiert werden. Dafür kann bei Altair der Diagrammtyp Histogramm als Spezialisierung des Balkendiagramms verwendet werden.
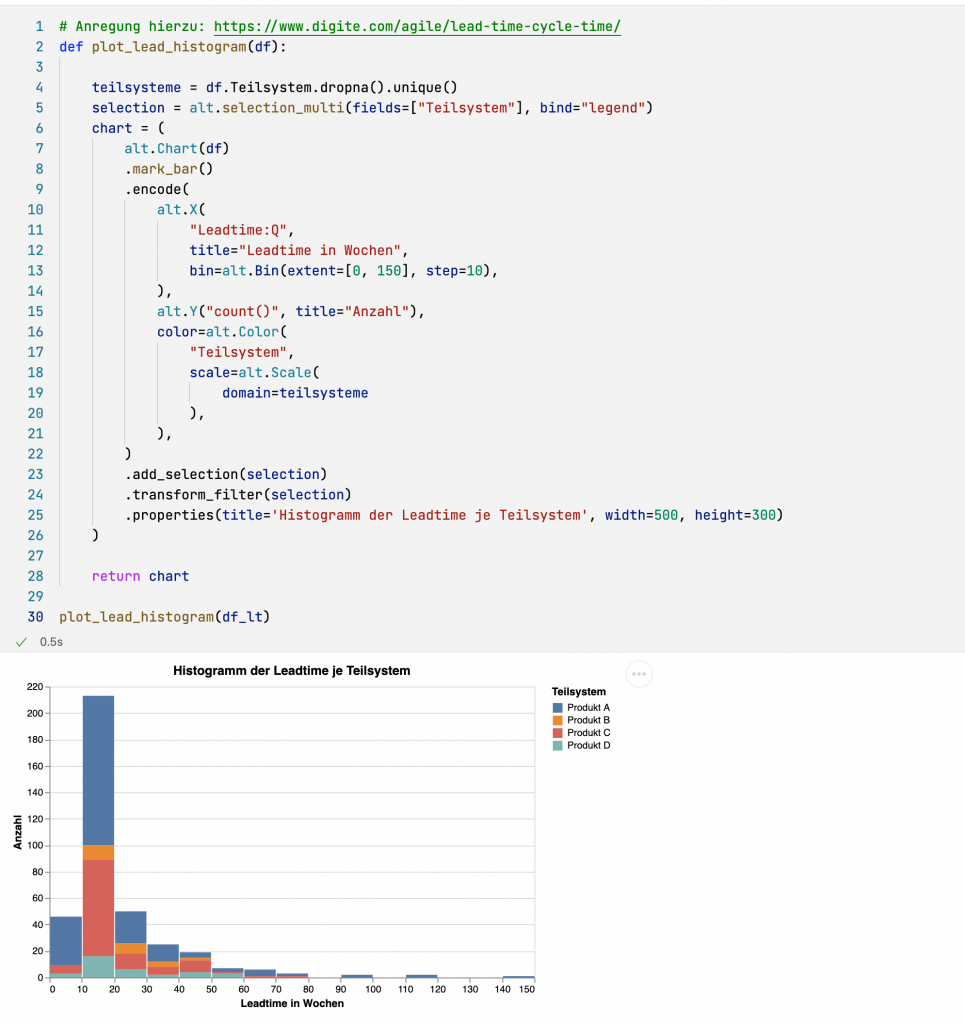
In Zeile (13) definiere ich die Größe der Klassen der Häufigkeitsverteilung für die Merkmalsausprägung Lead Time (Zeile 11).
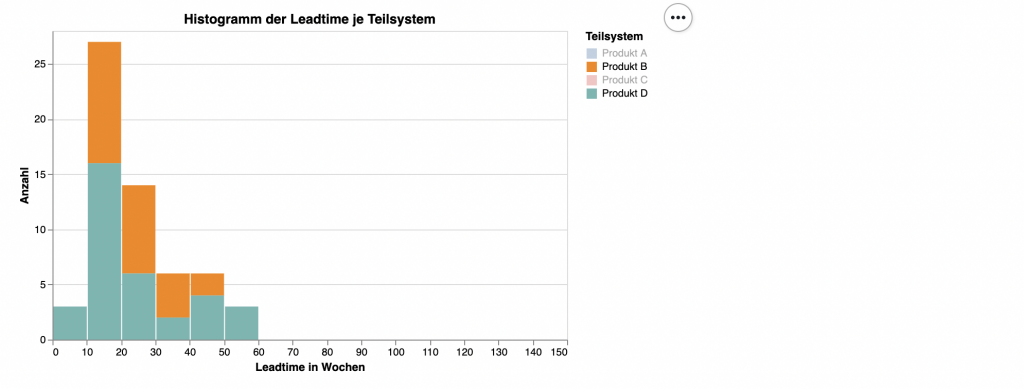
Als besondere Interaktion, möchte ich bei diesem Diagramm zur Laufzeit die Daten filtern können. Dazu ermittle ich in Zeile (4) alle Ausprägungen für das Markmal ‘Teilsystem’ und definiere in Zeile (5) eine Selektion, die an die Legende gebunden wird. Die Legende wird in Zeile 16–20 dem Merkmal ‘Teilsystem’ zugeordnet. Ein mögliches Ergebnis zeigt das folgende Bild.
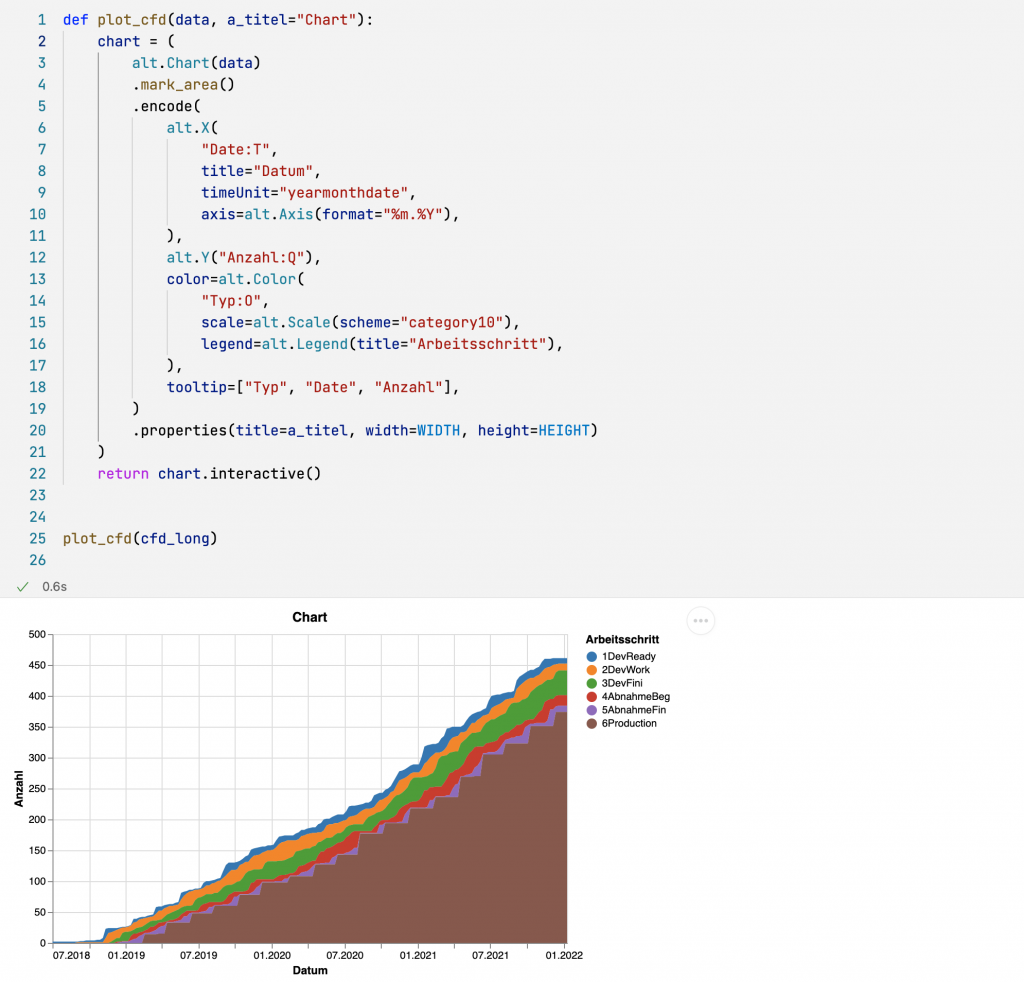
Agile Metriken: Cumulatives Flow Diagram
Kurz zur Erinnerung. Die Berechnung der Daten für das Cumulative Flow Diagram (CFD) lieferte uns ein DataFrame in der folgenden (breiten) Struktur:
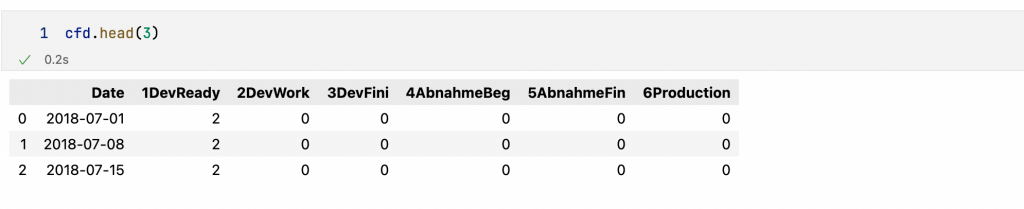
Altair erwartet die Daten jedoch im sogenannten langen Format (long format). In diesem Format stellt jede Zeile im DataFrame eine Beobachtung dar, wobei die dazugehörigen Metadaten ebenfalls als Werte abgelegt werden. Die Konvertierung erlegt die Methode melt, die jeder DataFrame hat.
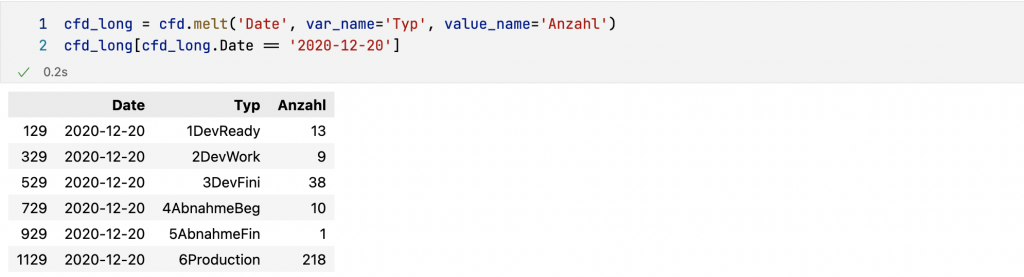
Für das Cumulative Flow Diagram müssen wir dann nur noch ein Area Chart erzeugen. Die Legende wird wieder über die Zuweisung zum Parameter color definiert. Die Legende wird alphanumerisch sortiert und legt damit auch fest, in welcher Reihenfolge die Daten im Area Chart übereinander gestapelt werden.
Abschluss
Dieser Blog-Artikel gibt Euch eine kleine Einführung in Altair – eine Python API zur Visualisierung von Daten. Altair ermöglicht einen schnellen Einstieg in die Erzeugung aussagekräftiger Diagramme. Die Bibliothek stellt nicht nur eine Vielzahl von Diagrammtypen zur Verfügung, sondern bietet darüber hinaus flexible Konfigurationsmöglichkeiten für die Gestaltung. Im Zusammenspiel mit Jupyter Notebooks können die Diagramme sehr schnell Schritt für Schritt entwickelt werden.
Die verwendeten Daten und die Jupyter Notebooks stelle ich wieder auf Github zur Verfügung. Ich wünsche euch viel Spaß beim Experimentieren.
Quellen
- Altair: Declarative Visualization in Python
- Altair Long Format: Long-form vs. Wide-form Data
- Blog Artikel Teil 1: Python: Datenanalysen mit Pandas und Co. – Teil 1
- Repository mit Beispieldaten und Quellcode auf Github
- Vega Color Schemes: Vordefinierte Farbschemata











