Früher oder später hat jeder damit in verteilten Systemen zu tun: Es gibt eine Änderung, die konsistent in mehreren Systemen ankommen muss. Dafür hat sich insbesondere in der Microservice-Welt das Outbox-Pattern durchgesetzt. In diesem Artikel geht es darum, wie so eine Outbox insbesondere bei hohen Lastanforderungen umgesetzt werden kann.

Warum Outbox-Pattern?
In der Zeit der großen Enterprise-Systeme wurden für solche Anwendungsfälle gerne verteilte Transaktionen (XA) mittels Two-Phase-Commit (2PC) eingesetzt. Dies kommt allerdings aus mehreren Gründen für moderne Anwendungslandschaften nicht in Frage. Vereinfach gesagt: Es ist zu kompliziert, zu langsam und koppelt die Systeme zu sehr aneinander.
Daher hat sich hier insbesondere in der Microservice-Welt das Outbox-Pattern durchgesetzt. Im Prinzip geht es darum, den Auftrag für eine Nachricht an andere Systeme bereits in der eigenen Transaktion festzuschreiben. Ein separater Thread liest, verarbeitet und quittiert diese Nachrichten nun wiederum in einer eigenen Transaktion. So wird in Summe sichergestellt, dass jede Nachricht mindestens einmal versendet wird.
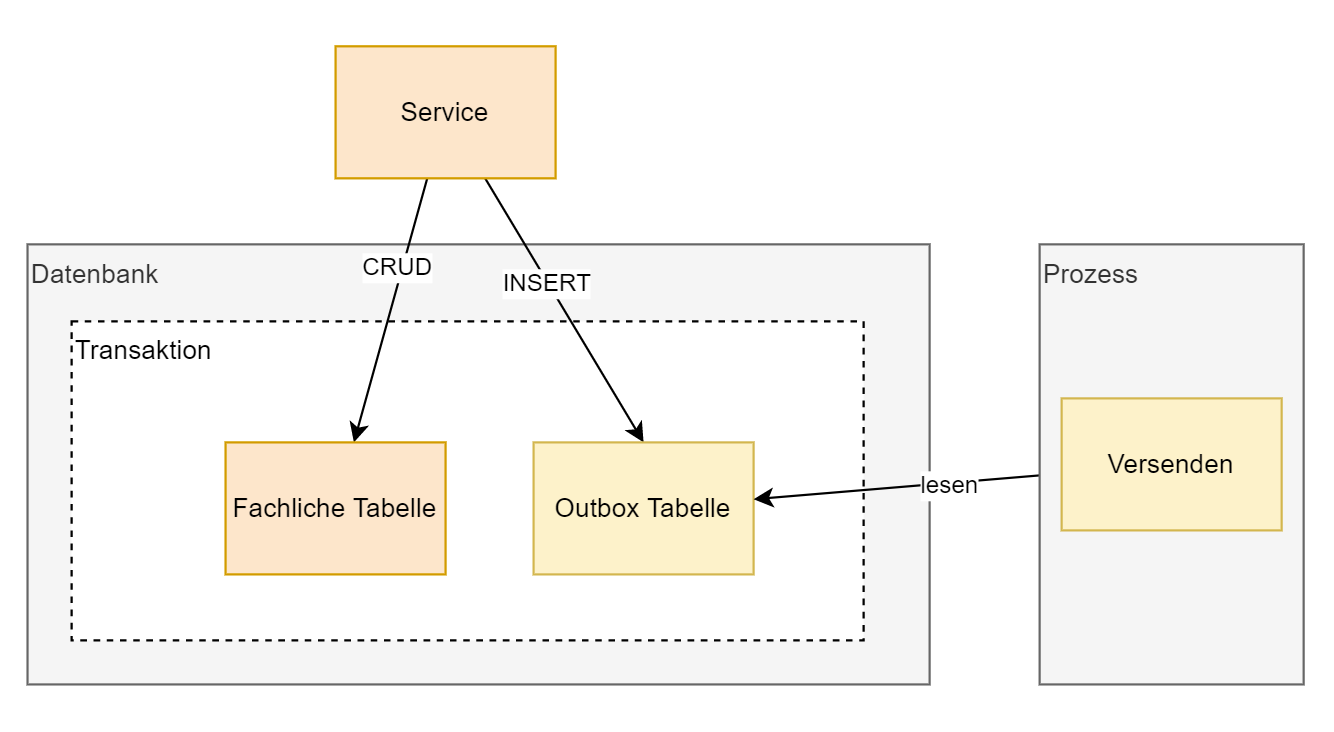
Für das Lesen gibt es mindestens zwei Möglichkeiten. Entweder ein Prozess überprüft regelmäßig diese Tabelle auf zu verarbeitenden Einträge (Polling) oder es wird versucht, auf Änderungen im Datenbank Log zu reagieren (Events). Um unabhängiger von der Datenbank zu sein, haben wir uns für simples Polling entschieden.
So einfach ist es dann doch nicht
Allerdings hat sich bei der Umsetzung gezeigt, dass es recht schnell kompliziert werden kann. Solange nur ein Prozess diese Aufträge verarbeitet, ist es einfach. Dieser liest einen Eintrag nach dem anderen und wenn es einen Fehler gibt, wird entweder wiederholt oder der nächste Auftrag verarbeitet. Kompliziert wird es, wenn mehrere Prozesse gleichzeitig versuchen, diese Outbox-Tabelle zu verarbeiten. Das ist natürlich nur nötig, wenn in der Anwendung schneller Aufträge generiert werden, als ein Prozess diese wiederum verarbeiten kann. Dies ist bei uns der Fall, da solche Aufträge in einer Vielzahl von Konstellationen auftreten können.
Für konkurrierenden Zugriffe hat man grundsätzlich die Wahl zwischen Optimistic Locking und Pessimistic Locking. Optimistic Locking scheidet hier aus, da die Kollisionshäufigkeit viel zu hoch ist.
Doch wieder nur ein Thread?
Beim Pessimistic Locking ist Vorsicht geboten, so dass es am Ende nicht doch wieder auf Sequentialisierung hinausläuft. Beispielsweise lässt sich durch Shedlock relativ leicht realisieren, dass sich nur ein Thread zur Zeit den nächsten Auftrag suchen darf. Dies führt aber dazu, dass quasi immer nur ein Thread aktiv arbeitet; die Arbeit geht lediglich reihum.
Wir brauchen also etwas, das mehr Concurrency erlaubt und nur auf Zeilenebene lockt. Eine Möglichkeit wäre, Datensätze explizit zu reservieren in einer eigenen Transaktion. Hier muss aber wiederum sichergestellt werden, dass keine Locks liegen bleiben bzw. diese verfallen können bzw. aufgeräumt werden.
Eine andere Möglichkeit bieten Oracle und Postgres. Andere relationale Datenbank bieten oft ähnlich Konzepte. Es ist möglich, beim Lesen des nächsten Auftrags diesen explizit zu locken und andere bereits gelockte Datensätze zu überlesen:

for update: Sorgt für ein Lock auf Row-Ebene.
skip locked: Findet nur Datensätze, die noch nicht gelockt sind.
Sieht doch gar nicht so kompliziert aus?
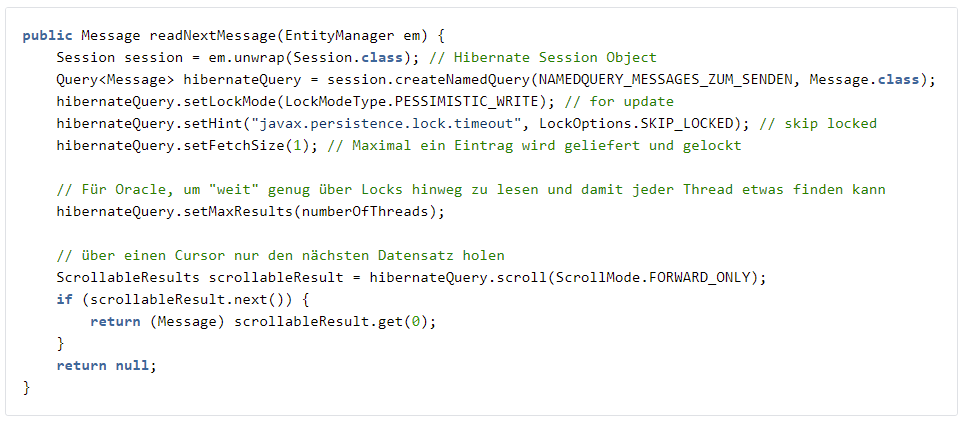
Etwas schwieriger wird es, wenn dies in Java realisiert wird. Zwar ist es mit JPA-Mitteln noch recht einfach möglich, das for update skip locked zu erzeugen. Eine weitere Dimension ist, dass sich jeder Thread nur einen Auftrag (bzw. wenige) in einem Schwung holen darf, da sonst die anderen Threads wieder nichts zu tun haben. Hier verhalten sich Postgres und Oracle grundsätzlich unterschiedlich. Während bei Postgres ein einfaches LIMIT für das Select reicht, muss bei Oracle mit einem Cursor gearbeitet werden. Letztlich geht das nicht mit JPA, sondern nur mit Hibernate (JBDC würde sicher auch gehen).
Fluch und Segen
Wenn die Lösung gefunden ist, sieht es gar nicht mehr so kompliziert aus. Nutzt die Datenbank und ihre Features für die konkurrierende Verarbeitung und ihr müsst Euch in der Anwendung nicht darum kümmern. Andere Lösungen haben ihre eigene Komplexität. Wir haben aber natürlich auch gesehen, dass dies recht Datenbank-spezifisch ist, auch wenn wir Hibernate benutzen. Andere Datenbanken verstehen vielleicht gewisse Hints nicht oder unterstützen manche Features nicht. Aber für unseren Kontext ist das ein guter Tradeoff. Wenn nochmal eine andere Lösung gebraucht wird, müssen wir nur sehr wenig austauschen, nichts ragt in die Anwendungslogik hinein.
Bei der Analyse hat sich aber auch gezeigt, dass es sich hier nicht um einen ausgetretenen Pfad handelt. Habt ihr solche Herausforderungen schon lösen müssen? Wie seid ihr vorgegangen? Schreibt mir gern auf LinkedIn oder Xing. Ich bin neugierig und gespannt.











